Lecture 2.1 Outer Alignment: Reward Misspecification | October 3rd, 2023
Markov Decision Process
Environment at time t is in a state S. Agent receives a scalar reward R after an action A. Choose an action that leads to the best reward. Reward is used as a training signal to tune neural network.
RL Challenges
- Sparse and delayed rewards (coast-runners game)
- Partial observability / exploration vs. exploitation
- Non-stationary (dynamic environments)
- Sim-to-real transfer (humans evaluate if desired output is achieved, instead of using reward)
- Sample efficiency / computational cost
AI Alignment
“How can we make sure the thing does what we want it to do?”
(Outer) misalignment examples:
- Unintended “solutions” to be deployed problems (coast runner)
- Flawed reward design (not accounting for bias in training data)
The goal of differentiating undesirable vs. desirable novel solutions: human evaluations are limited.
→ How do we capture the human concept of a given task in a reward function?
LLMs
- Supervised learning, abstracts human language based on correlation and statistical patterns in the training data
- Can generate text based on statistical likelihood and patterns in the data.
Initial “raw” LLM → two sample responses → human eval → Safe LLM (aligned with RLHF).
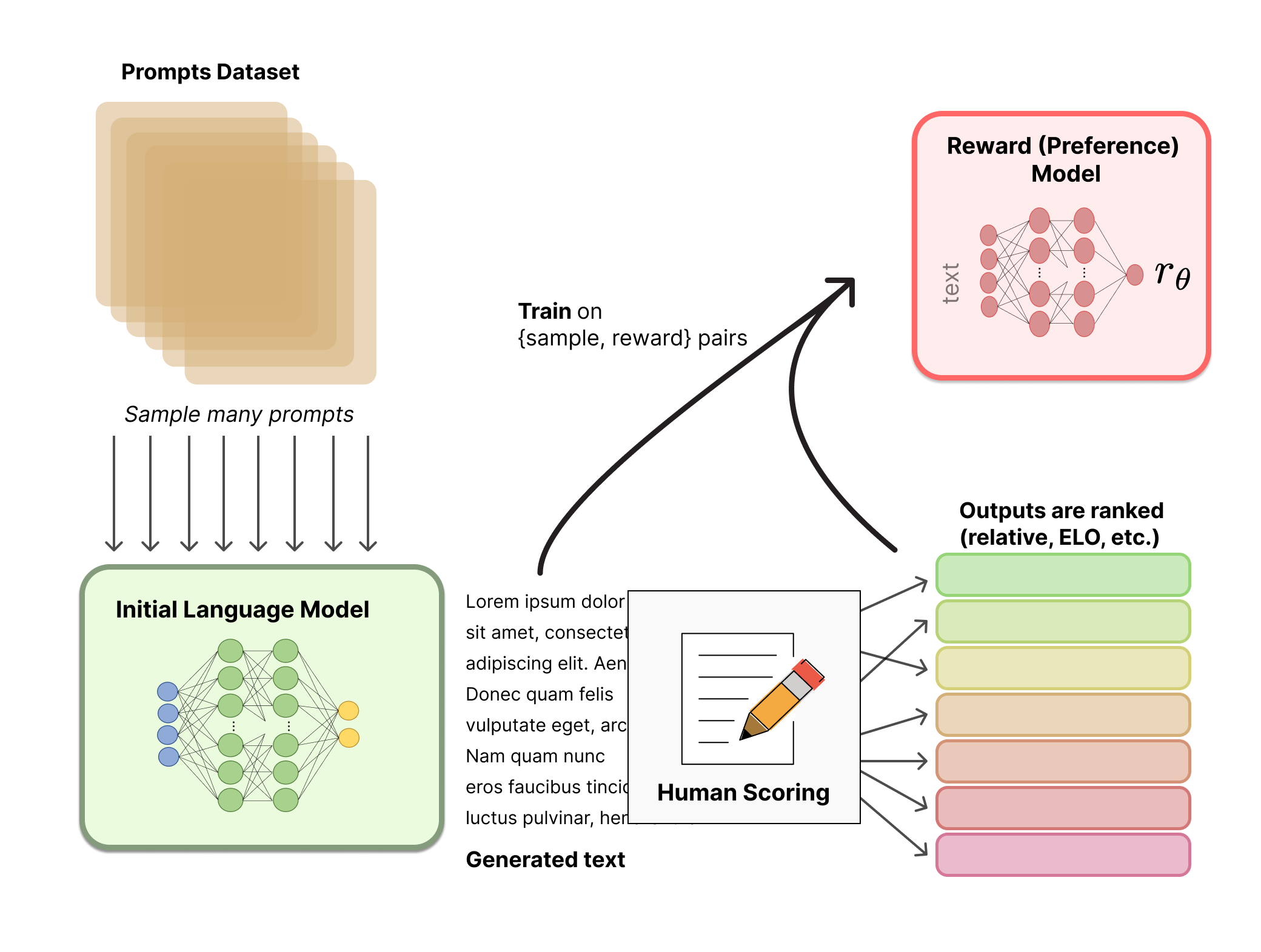
Challenges with RLHF:
- RLHF degrades model output accuracy
- Human preferences could be influenced by bad actors / only an estimation (how do we determine proper human preference?)
- Neglecting: inner misalignment
Goodhart’s Law
When a measure becomes a target, it ceases to be a good measure. Proxy objectives (e.g. scalar reward) lead to optimizations towards proxy goals
-
Goal: Examine students
- Proxy Metric: Test scores → can lead to learning for tests and not for comprehension
-
Goal: Win a democratic election
- Proxy metric: Votes → can lead to over-claimed promises
-
Goal: Find a good function approximation
- Proxy Metric: Deviation between data points and function → overfitting
-
Goal Align AI systems with human preferences
- Proxy metric: preference model from human feedback → sycophancy, model degradation, insufficient alignment (generalization is worse)
Research Question: How is model over-optimization affected by model sizes?
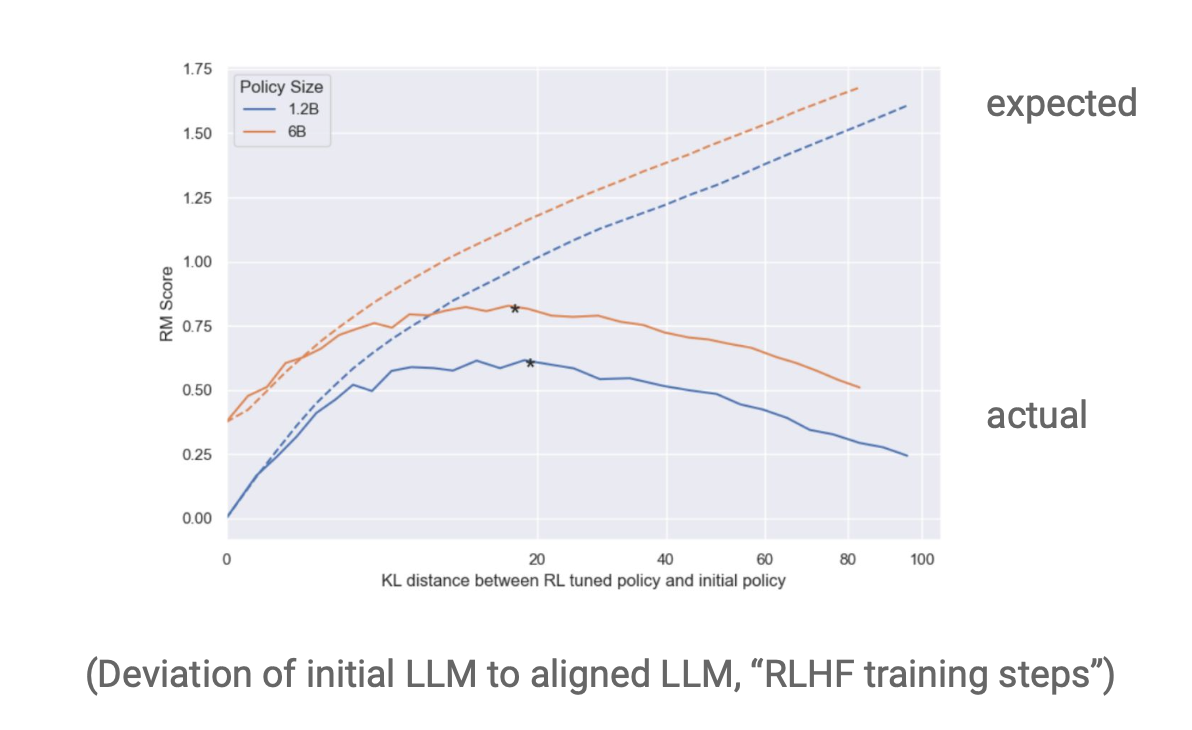
Goal: Understand the amount of overfitting and how it scales for safe model optimization
- Number of human annotator samples reduces overfitting