Overview
- Review of reinforcement learning
- Intro to Inner Alignment
- Goal Misgeneralization
- Mesa Optimization
- Pseudo Alignment
- Proxy Alignment
Reinforcement Learning
- Reward Hypothesis: All goals can be described by maximizing an expected cumulative Reward
- Not supervised or unsupervised learning
- Agent makes decisions sequentially and receives feedback after
- Agent only knows standing through reward signal
- Goal → choose actions to maximize expected total future reward
- Key Terms:
- Policy → Behavior function which maps state to action - deterministic or stochastic
- Value Function → Represents how good each state/action is
- Model → Agent’s representation of the environment
Challenge of Sequential Decision-Making (& RL): Learning vs. Planning
- When the environment is unknown, the agent needs to explore the environment to improve its Policy* When the environment is known, the agent acts within what it knows to improve its reward, and then its policy → specification gaming
- Is specification enough - does the reward incentivize the AI to pursue the correct goal?
Inner alignment is getting AI to pursue the goal we want, whereas outer alignment concerns defining the goal we want.
Goal Misgeneralization
- Goal misgeneralization: learned model behaves as though it is optimizing an unintended goal, despite receiving correct feedback during training
- Correct specification: defining the objective
- Correct Goal: ensuing the AI understands and acts to achieve the objective
- Goal misgeneralization is when AI has the correct specification but the wrong goal
- Model capabilities generalize, but the pursued goal does not
Goal Misgeneralization Example
- Follow the Leader → RL agent learns to follow the expert, not to learn the order, but performed well in training
- Monster Gridworld RL environment is 3D gridworld where agent must college apples (+1 reward) while avoiding monsters (-1 reward)
- First 25 steps have monsters, so agent always optimizing for shields in training environment
- In testing, Train25 therefore is maximally misgeneralized - going for shields always
- Does well in training, and appears to pursue optimal policy, but does not in practice
Mesa Optimization
- When ML systems are trained, an objective function captures our goal and a learning algorithm optimizes the system for that goal
- Difference between what an agent is optimized for (purpose) versus if the agent optimizes something else
-
Optimizers: A system that searches through a space of possible solutions for the elements that score high according to the objective function
- Learning algorithms are optimizers because search through space of possible parameters and improve the parameters with respect to some objective
-
Optimizers can create other optimizers
- A neural network that runs a planning algorithm that predicts the outcome of different business strategies and searches for ones that have the best predicted outcome
- Base-optimizer: an optimizer that runs another optimizer
- the learning algorithm for the neural network above (some sort of gradient descent)
- Mesa-Optimizer: optimizer being ran by another optimizer
- Neural network running the planning algorithm Mesa-optimization: when a base optimizer finds a model that is itself an optimizer
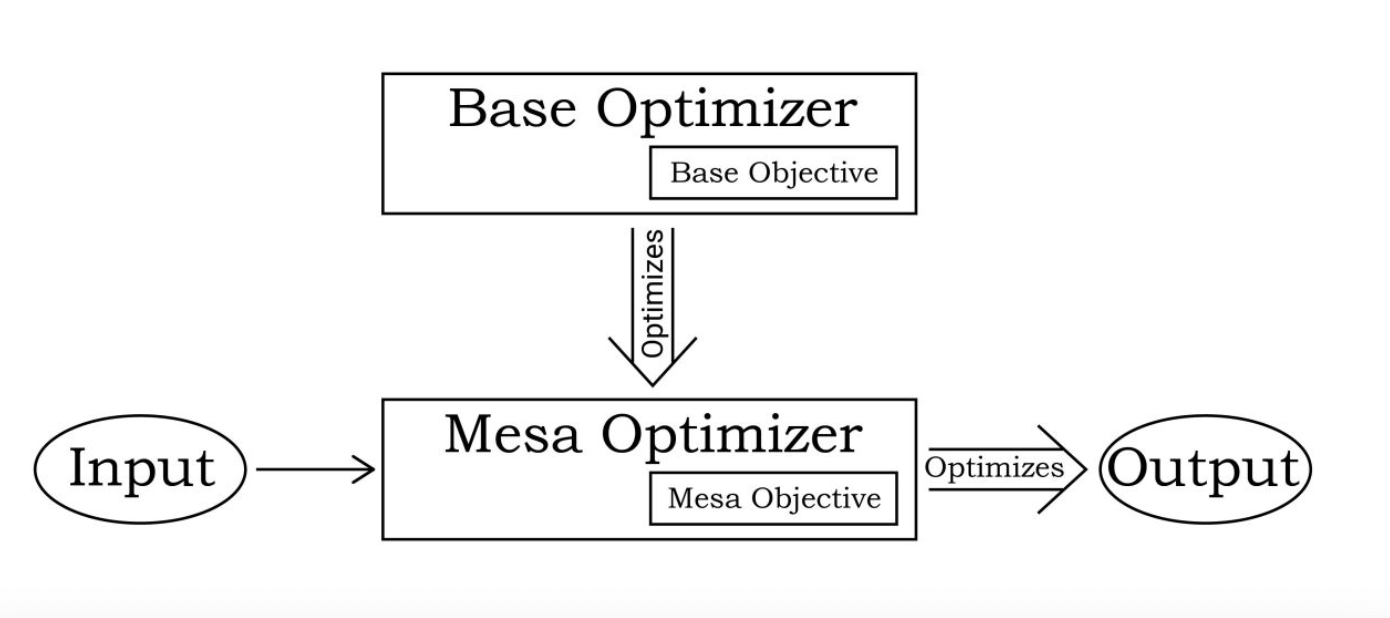
- Neural network running the planning algorithm Mesa-optimization: when a base optimizer finds a model that is itself an optimizer
-
Base objective → the objective function that the base optimizer uses to rate systems
- ML example: Base optimizer would be gradient descent, base objective would be the loss function
- Base objective is specified by the programmer
Mesa Objective → whatever function the mesa-optimizer uses to select between different possible outputs/actions
- Example: mesa-optimizer would be a neural net optimizer, mesa objective would be whatever is found by the base optimizer to produce a good performance in the training environment
Alignment challenge when there is a gap between base and mesa-objective