Lecture 2.2 Outer Alignment: Intelligence and Goals | October 6th, 2023
Experiment
Research Question: Do RL agents seek power? (as in having more options)
Defining power:
- The ability to achieve a range of goals (philosophical)
- Optimal Policy to achieve goal given a reward function (RL)
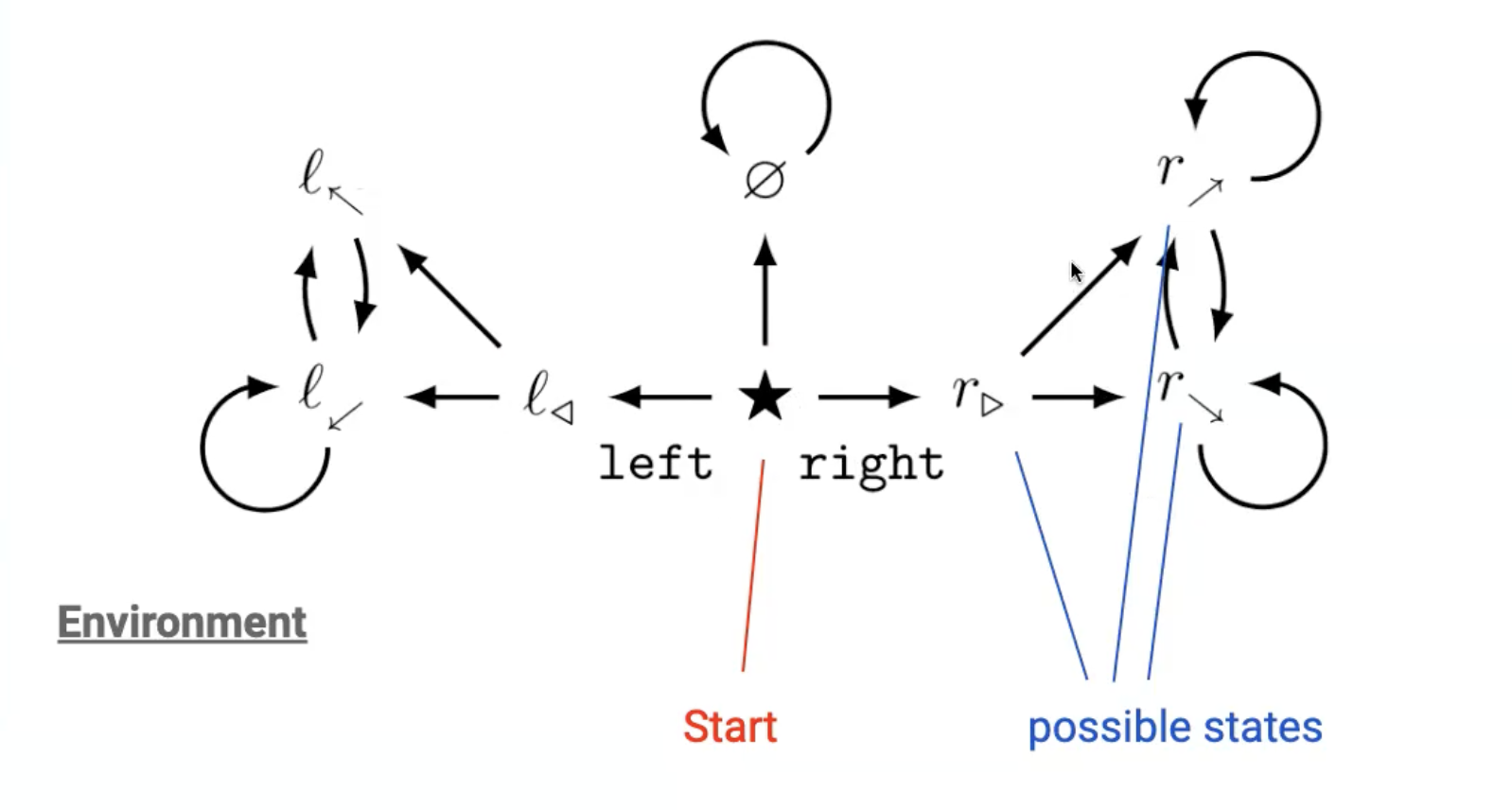
Setup:
- Study RL agent in environment setup with dead ends and loops
- Consider all possible state-based reward function for all states
- A state-based reward function would give each state a reward for being in that state
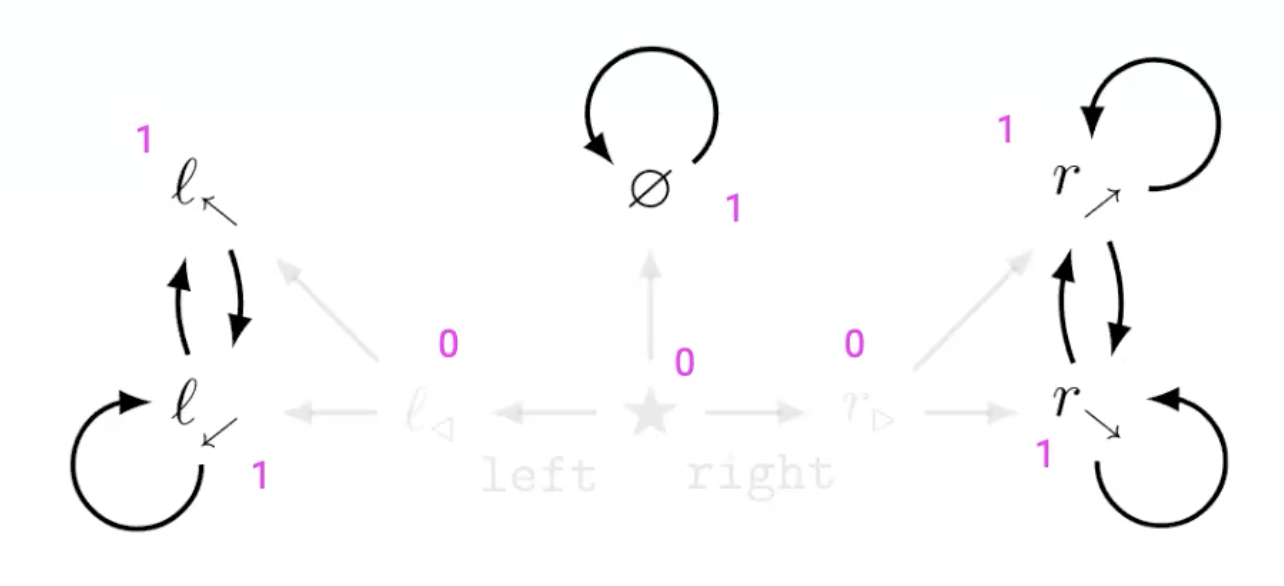
If I look at all possible reward functions, is there a preferred state?
- → Yes! being in right half is better (more optimal)
- → Resulting inequality “pulls” agent for all reward functions
- → Caused by (a) symmetries in the environment
- → do AI agents have goals?
Result:
- Statistical tendency of optimal policies in RL to having more options
- NOTE: they assume complete observability in the Markov Decision process
Philosophy
1) “intelligence and final goals are orthogonal: more or less any level of intelligence could in principle be combined with more or less any final goal”
States/assumes:
- → Relationship between motivation and intelligence is unrelated
- → Any level of intelligence could be combined with (almost) any final goal
Orthogonality thesis
Assumptions:
- (Super) intelligent agents have goals
- Intelligence = power, as more cognitive resourcefulness
- It’s easier to create intelligent problem solving skils than encode human-like values and dispositions
Argument:
- Intelligent search for optimal policies can be performed in the service of any goal
This implies that AI can have non-human (incomprehensible) goals.
2) “several instrumental values can be identified which are convergent in the sense that their attainment would increase the chances of the agent’s goal being realized for a wide range of final goals and a wide range of situations, implying that these instrumental values are likely to be pursued by a broad spectrum of situated intelligent agents”
States/assumes:
- → (Super)intelligent agents have a wide set of possible final goals
- → (Super)intelligent agents will pursue similiar intermediary (instrumental) goals
Instrumental Convergence
Assumptions:
- (Super)intelligent agents have (long-term) goals
Argument (what goals could be instrumental)?
- Actions increasing the probability of agent doing actions in the future to achieving its goal are favorable → creates reason for the agent to be in the future
- If goal is truly final, would like to keep that goal unaltered → resistance to steps that alter financial goal
- If more resources increases probability of achieving its goal → creates reason for acquiring resources / power
This implies Powerful AI should be hard to control.
Search for Misalignment?
Problem
- How to evaluate the goals of a LLM? → with lots of inputs and outputs, but too expensive
- Research question: can we evaluate LLMs with model written evaluations? can we test success of RLHF for alignment?